 高招云直播
高招云直播
本次发布的百灵全模态大模型Ming-flash-omni-2.0,基于Ling-2.0(MoE 架构,100B-A6B)架构训练。相比之前发布的 Preview 版本,Ming-flash-omni-2.0 实现了全模态能力的代际跃迁,无论是在复杂的视觉理解、充满情感的语音交互,还是极具创意的图像
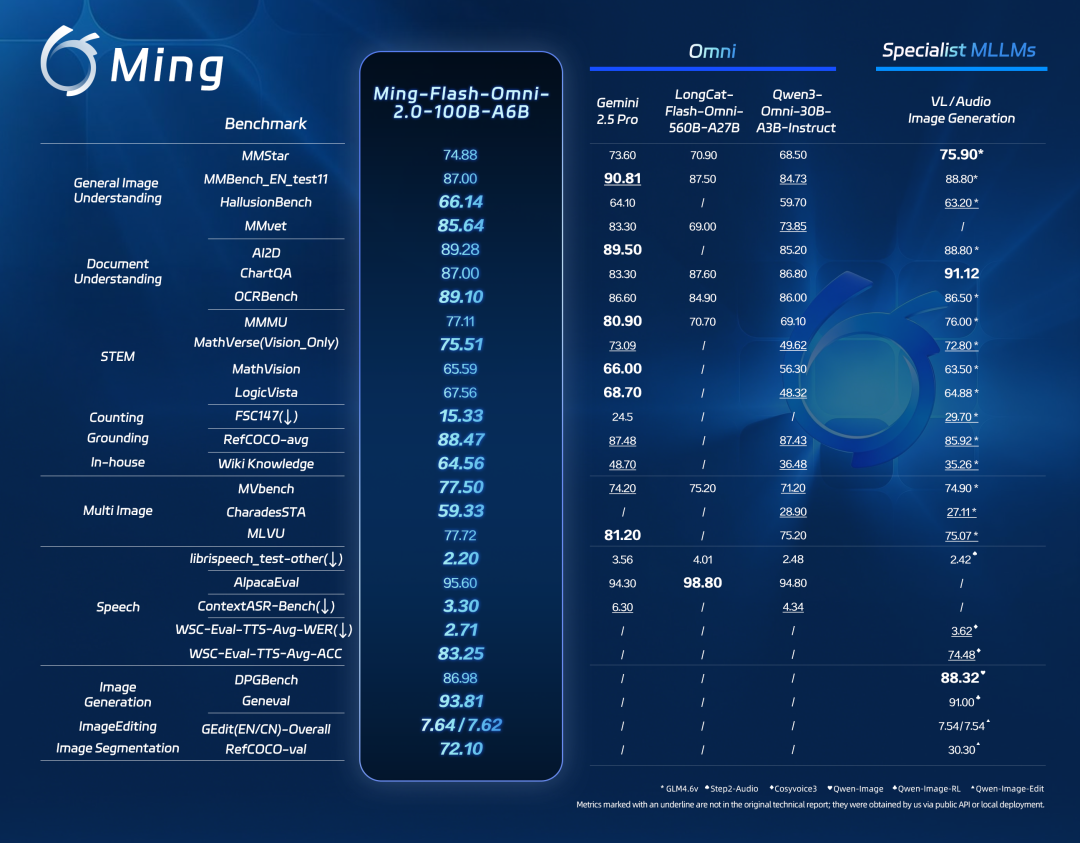
长期以来,多模态大模型领域存在一个难题:通用的“全模态大模型”(Omni-MLLMs)往往在特定领域的表现不如“模态专用大模型”(Specialist MLLMs)。Ming-omni 系列的研发初衷,正是为了填补这道鸿沟。从 Lite 版本到 Flash Preview,我们验证了模型规模对性能的提升作用;而从 Preview 到如今的 2.0 版本,我们通过海量
详情查看
感知无界·创造有形:百灵全模态 Ming-flash-omni-2.0 焕新生活想象
二、我们发布并开源首个混合线性架构的万亿参数思考模型Ring-2.5-1T
作为迈向通用智能体时代的关键步骤,我们将混合线性注意力架构在预训练和强
相比此前发布的 Ring-1T,Ring-2.5-1T 在生成效率、思考深度、长程执行上均有大幅提升:
高效生成:得益于高比例的线性注意力机制,在超过 32K 生成长度下,访存规模降低 10 倍以上,生成吞吐提升 3 倍以上,尤其适合深度思考和长程执行的任务。
深度思考:在 RLVR 基础上引入dense reward来反馈思考过程的严谨性,使得 Ring-2.5-1T 同时实现IMO 2025和CMO 2025 的金牌水平(自测)。
长程执行:通过大规模fully-async agentic RL训练,显著提升针对复杂任务的长程自主执行能力,使得 Ring-2.5-1T 可以轻松适配 Claude Code 等智能体编程框架和 OpenClaw 个人 AI 助理。
深度思考与长程执行
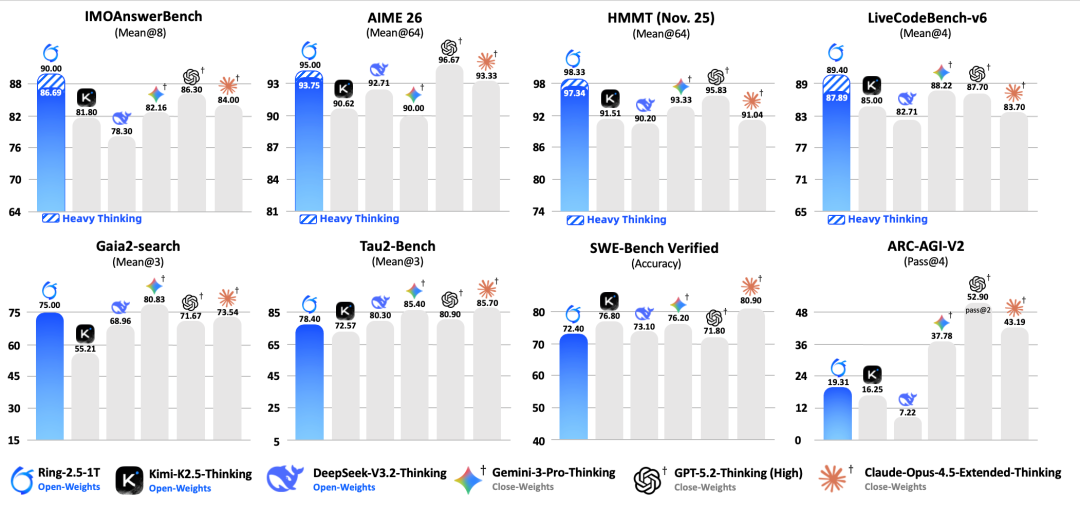
为评估 Ring-2.5-1T 的深度思考和长程执行能力,我们选取了具有代表性的开源思考模型(DeepSeek-v3.2-Thinking、Kimi-K2.5-Thinking)和闭源API(GPT-5.2-thinking-high、Gemini-3.0-Pro-preview-thinking-high、Claude-Opus-4.5-Extended-Thinking)作为参考。 Ring-2.5-1T 在数学、代码、逻辑等高难推理任务(IMOAnswerBench、AIME 26、HMMT 25、LiveCodeBench、ARC-AGI-V2)和智能体搜索、
软件工程 、工具调用等长程任务执行(Gaia2-search、Tau2-bench、SWE-Bench Verified)上均达到了开源领先水平。我们还额外
测试 了深度思考模式(heavy thinking mode),通过在推理过程中扩展并行思考与总结,实现测试 时扩展,从而有效提升推理的深度与广度。在 IMO 2025(满分 42 分)中,Ring-2.5-1T 获得 35 分,达到金牌水平;在 CMO 2025(满分 126 分)中取得 105 分,显著高于金牌线(78 分)及国家集训队入选线(87 分)。对比 Ring-2.5-1T 与 Ring-1T 的答题结果可以发现,前者在推理逻辑严谨性、高阶数学证明技巧使用以及答案表述完整性方面均有明显提升。我们现已公开 Ring-2.5-1T 在 IMO 2025 与 CMO 2025 中的详细解答,完整内容可通过以下链接查看:https://github.com/inclusionAI/Ring-V2.5/tree/main/examples
此外,在挑战性的智能体搜索 GAIA2-search 任务中,Ring-2.5-1T 达到开源 SOTA 水平。GAIA2 环境强调跨应用工具协作与复杂任务执行能力,Ring-2.5-1T 在规划生成与多步工具调用上的效率与准确性均表现突出。
三、我们发布并开源Ling-2.5-1T
深度思考模型(thinking model)拉升智能上限,即时模型(instant model)则凭效率与效果的平衡拓宽智能覆盖,它让 AGI 不只更强,也更普惠。作为百灵家族最新的旗舰级即时模型,Ling-2.5-1T 在模型架构、token 效率、偏好对齐等维度全面升级,期待为用户带来更优质的普惠智能体验。
万亿参数与百万上下文:Ling-2.5-1T 具有 1T 总参数(激活 63B),预训练语料从前代的 20T 扩展至 29T,凭借高效的混合线性注意力架构与精细的
数据 策略优化,模型能够以高吞吐处理长达 1M token 的上下文。
更高的 token 效率:引入“正确性 + 过程冗余”复合奖励机制,进一步拓展了即时模型效率与效果的平衡边界。在相同 token 效率条件下,Ling-2.5-1T 的推理能力显著超越前代,接近需消耗约 4 倍输出 token 的前沿思考模型水平。
精细化偏好对齐:通过引入双向强
化学 习反馈、Agent-based 指令约束校验等精细化对齐策略,使 Ling-2.5-1T 在创意写作、指令遵循等偏好对齐类任务上相比前代模型实现大幅提升。
高效的原生智能体交互:基于大规模高保真交互环境进行 Agentic RL 训练,Ling-2.5-1T 可适配 Claude Code、OpenCode、OpenClaw 等主流智能体
产品 。在通用工具调用基准 BFCL-V4 上达到开源领先水平。
我们全面评估了 Ling-2.5-1T 在知识、推理、智能体交互、指令遵循、长文本处理等多个权威基准评测上的表现。Ling-2.5-1T 与前代模型 Ling-1T 对比,实现了全方位的能力提升,是百灵家族当前最强大的即时模型。在与主流的大尺寸即时模型(DeepSeek V3.2、Kimi K2.5、GPT 5.2)对比中,Ling-2.5-1T 在复杂推理、 指令遵循能力具有明显优势。
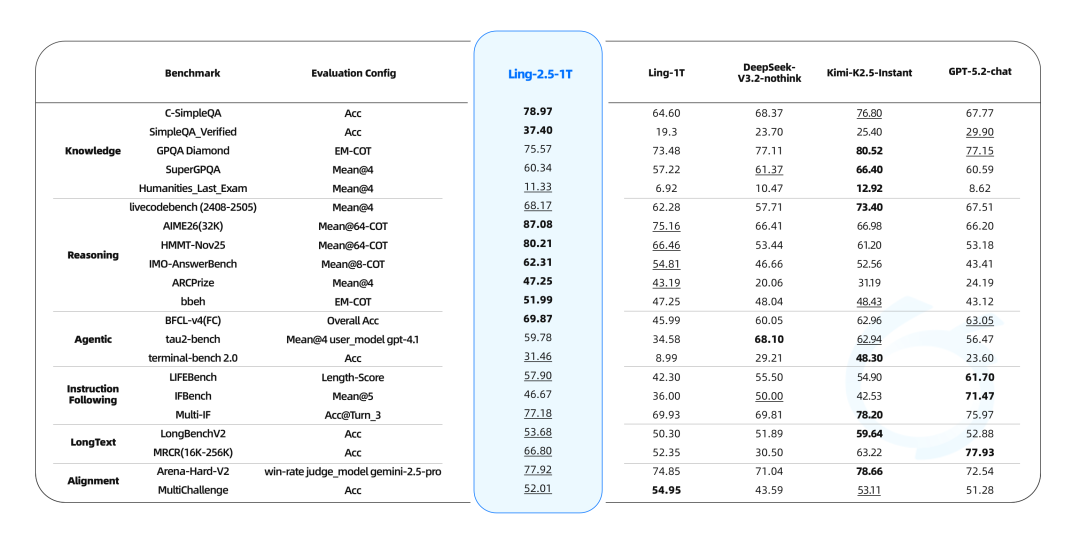 详情查看Ling-2.5-1T,普惠智能,即时响应更多百灵大模型相关资讯请前往⬇️
详情查看Ling-2.5-1T,普惠智能,即时响应更多百灵大模型相关资讯请前往⬇️






