 高招云直播
高招云直播
腾讯混元宣布开源首个混合推理MoE模型「Hunyuan-A13B」,这是业界首个13B级别的MoE开源混合推理模型。效果比肩顶尖开源模型的同时,大幅降低推理延迟与计算开销,让开发者可以用更低门槛的方式获得更好的模型能力。
腾讯混元坚定拥抱开源,未来将持续推进多尺寸、多场景的全系模型开源。
积极促进开源生态繁荣的腾讯混元团队长期持续热招中!
我们有着充沛的算力资源、丰富的训练数据,以及腾讯业务生态下多元的应用场景,给予你不设上限的战场和空间。
期待更多志同道合的优秀人才加入混元,与我们一起探索智能上限、构建向善的AGI!
社招岗位
大模型精调算法工程师-代码方向北京/深圳/上海
大模型预训练算法研究员/专家研究员北京/深圳
大模型算法工程师-推理能力方向北京/深圳
大模型算法专家-Agent&长文本北京
大模型应用算法工程师北京/深圳
大模型精调算法工程师-问答&RAG北京/深圳
大模型精调算法工程师-RAG可信方向北京/深圳

青云计划热招岗位
感兴趣的事业群和部门选择:
TEG-腾讯混元大语言模型部
技术研究-机器学习方向/自然语言处理方向/多模态方向/多媒体处理方向 深圳/北京
 腾讯混元大模型家族迎来新成员——混元-A13B模型发布并开源。
腾讯混元大模型家族迎来新成员——混元-A13B模型发布并开源。作为基于专家混合(MoE)架构的大模型,总参数800亿、激活参数130亿,在效果比肩顶尖开源模型的同时,大幅降低推理延迟与计算开销。
这对个人开发者和中小企业来说,无疑是个好消息,极端条件下仅需1张中低端GPU卡即可部署。用户可以在Github、HuggingFace等技术社区下载使用(https://github.com/Tencent-Hunyuan),模型API已在腾讯云官网上线。
 先试试数学推理,例如输入“9.11和9.9谁大”,模型准确完成小数比较,并展现分步解析能力。
先试试数学推理,例如输入“9.11和9.9谁大”,模型准确完成小数比较,并展现分步解析能力。
对于时下热门的智能体(Agent)应用,模型可调用工具,高效生成出行攻略、数据文件分析等复杂指令响应。
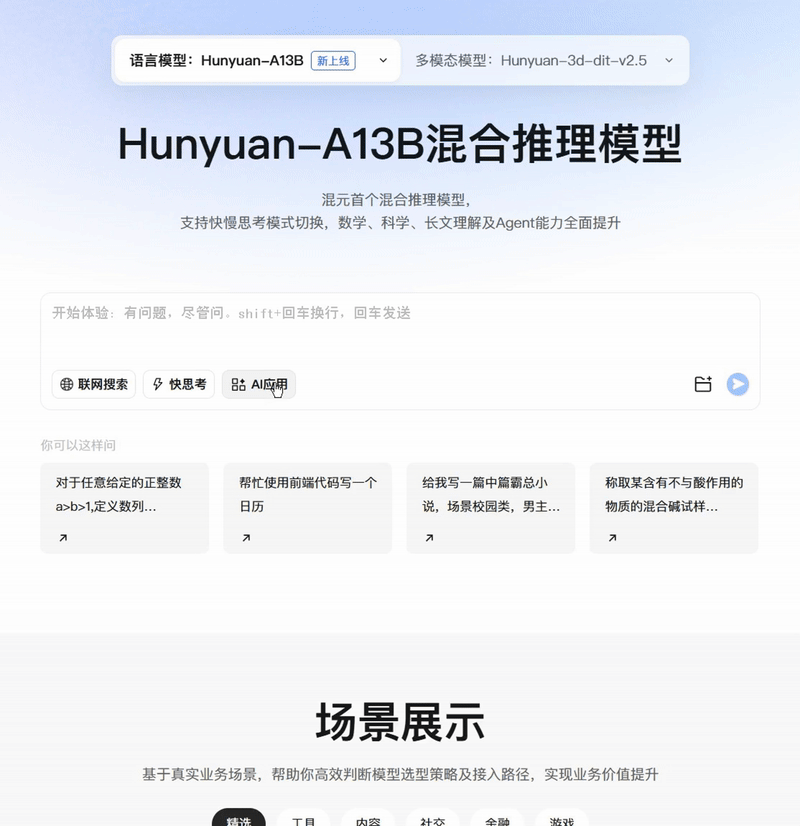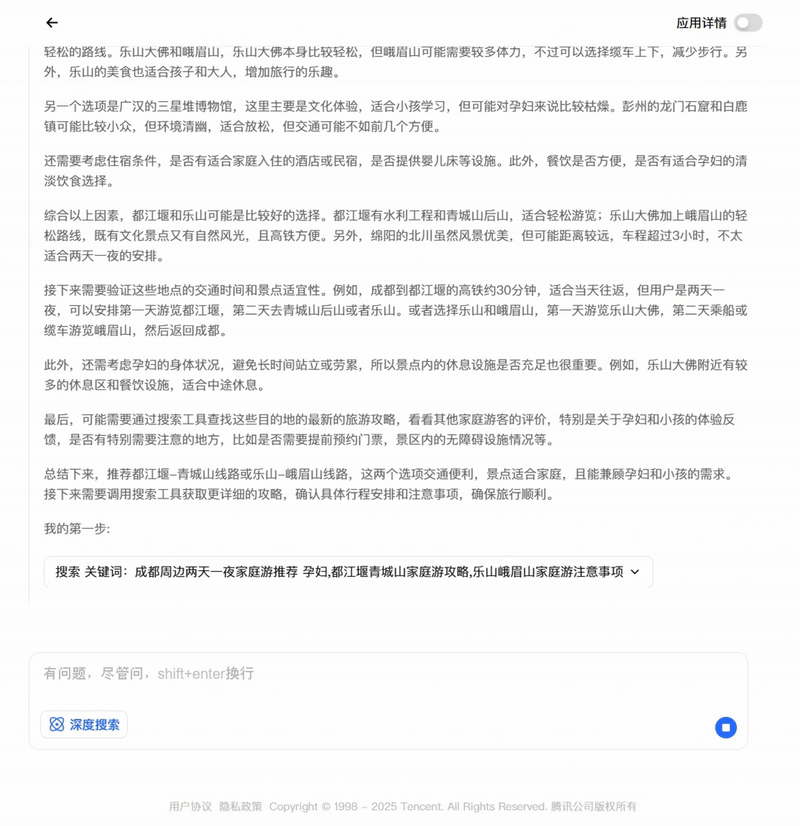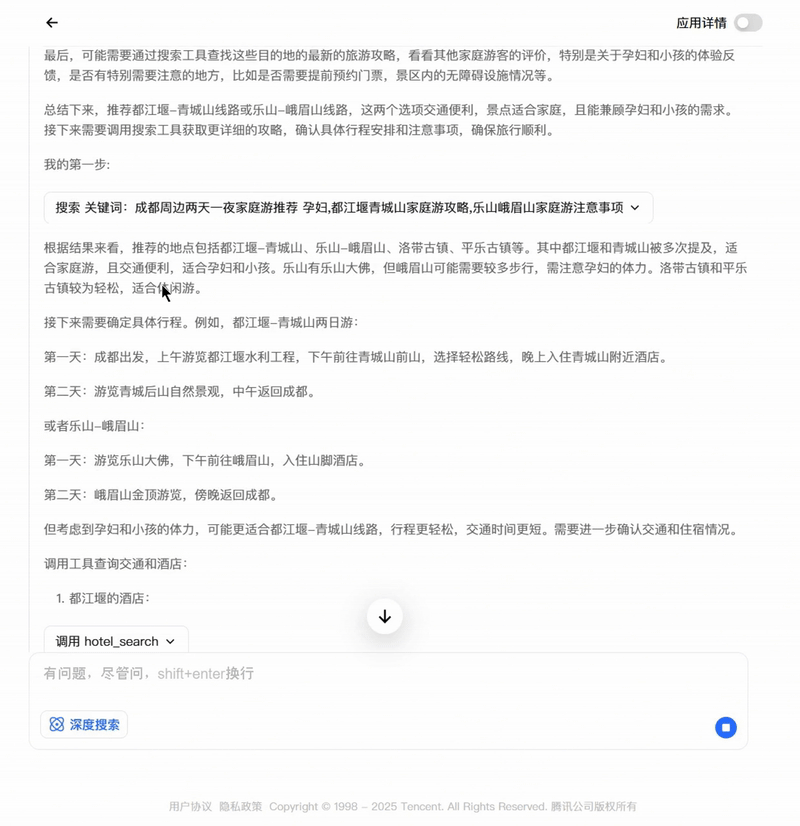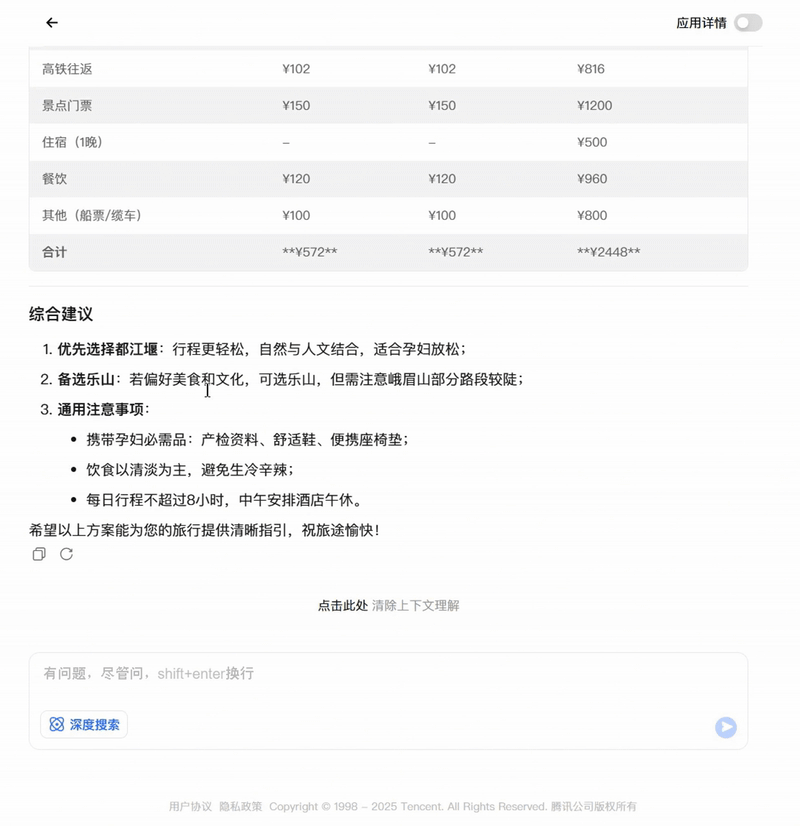
用模型生成的出行攻略
再看数据和效果。在多个公开数据测试集上,模型在数学、科学和逻辑推理任务上表现出领先效果。
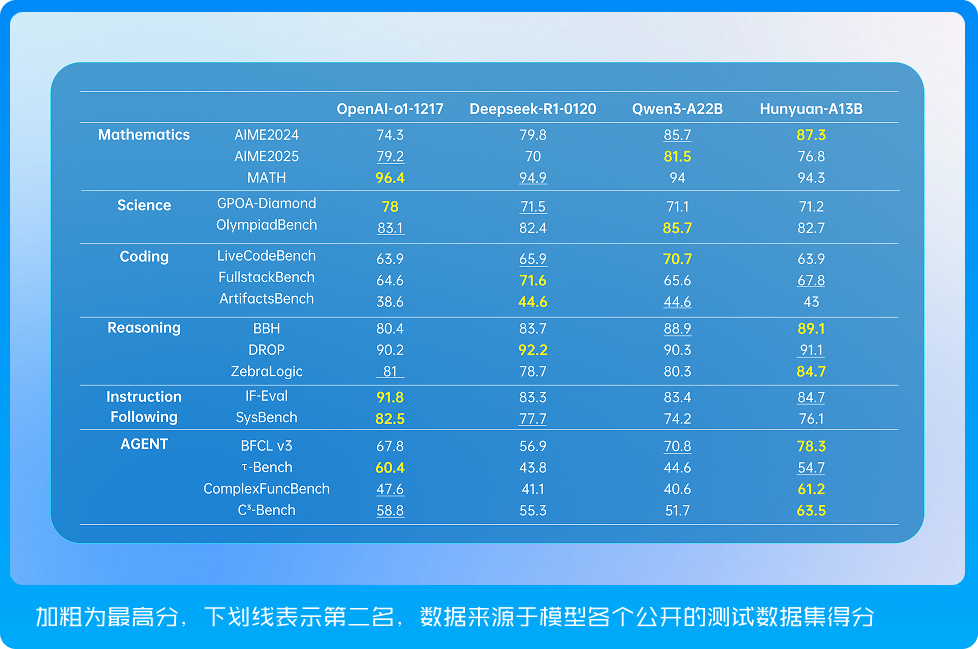

当前 AI大模型迅速发展,但行业也存在高昂的部署成本等现实问题。混元-A13B模型通过MoE架构,为每个输入选择性地激活相关模型组件,不仅与同等规模的密集模型相比又快又省,而且为个人开发者和中小企业提供了一个可扩展且高效的替代方案,使得他们能够以更低的门槛,充分利用前沿大模型的能力来驱动创新和业务增长。
这背后源自混元-A13B模型的技术创新。
比如:预训练中,模型用了20 万亿高质量网络词元语料库,提升了模型推理能力的上限;完善了MoE 架构的 Scaling Law(即规模定律)理论体系,为 MoE 架构设计提供了可量化的工程化指导,提升了模型预训练效果。
再比如:用户可以按需选择思考模式,快思考模式提供简洁、高效的输出,适合追求速度和最小计算开销的简单任务;慢思考模式涉及更深、更全面的推理步骤。这优化了计算资源分配,兼顾效率和准确性。
混元还开源了两个新数据集,以填补行业内相关评估标准的空白。其中,ArtifactsBench主要用于代码评估,构建了一个包含 1825个任务的新基准;C3-Bench针对Agent场景模型评估,设计了1024条测试数据,以发现模型能力的不足。
混元-A13B模型,是继混元Large模型后,推出的又一重要开源模型。接下来,混元也将推出更多尺寸、更多特色的模型,将更多实践技术与社区共享,促进开源生态的繁荣。
体验入口:https://hunyuan.tencent.com/
API地址:https://cloud.tencent.com/product/tclm
Github :https://github.com/Tencent-Hunyuan
HuggingFace:https://huggingface.co/tencent
C3-Bench:https://github.com/Tencent-Hunyuan/C3-Benchmark
ArtifactsBench:https://github.com/Tencent-Hunyuan/ArtifactsBenchmark




